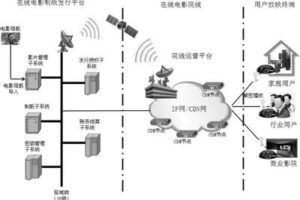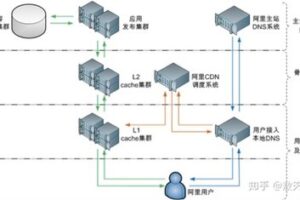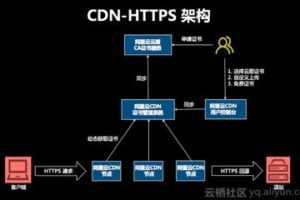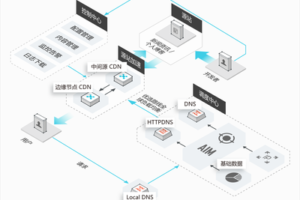
以下是一些知名的网络爬虫列表(不包括所有,且可能随时间变化):
-
Googlebot:谷歌搜索引擎的爬虫,用于抓取网页内容以更新谷歌搜索索引。
-
Bingbot:微软Bing搜索引擎的爬虫,用于索引网页内容。
-
Slurp(现为DuckDuckBot):DuckDuckGo搜索引擎的爬虫,用于抓取和索引网页。
-
Baiduspider:百度搜索引擎的爬虫,用于抓取中文网页内容。
-
YandexBot:Yandex搜索引擎(主要服务于俄罗斯市场)的爬虫。
-
Sogou Spider:搜狗搜索引擎的爬虫,用于抓取中文网页内容。
-
Exabot(现为Internet Archive的爬虫之一):曾经是一个独立的搜索引擎爬虫,现在被用于Internet Archive的项目中。
-
Nutch:一个开源的搜索引擎爬虫,常被用于构建自定义搜索引擎。
-
Scrapy:虽然不是一个特定的爬虫,但它是一个流行的Python库,用于编写网络爬虫来抓取网站数据。
-
MajesticSEO(现为Majestic):一个提供网站分析和SEO服务的公司,其爬虫用于收集网站数据。
-
AhrefsBot:Ahrefs网站分析工具的爬虫,用于抓取网页链接和数据。
-
SemrushBot:Semrush竞争情报和SEO分析工具的爬虫。
-
MJ12bot:Majestic-12(一个网站分析和链接检查服务)的爬虫。
-
DotBot:Mozilla的爬虫,用于支持其开源项目和研究。
-
CommonCrawl:一个开源的网络爬虫项目,定期抓取互联网上的大量数据,并供公众使用。
请注意,这个列表只是众多网络爬虫中的一小部分,而且爬虫的具体名称和行为可能会随着时间和版本更新而发生变化。
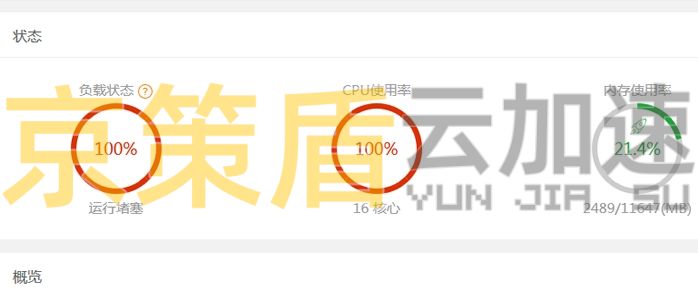
使用京策盾高防CDN可以完美杜绝这个问题,京策盾高防CDN已经内置了各种主流蜘蛛与恶意蜘蛛库,可以做到一键放行和拦截,避免您修改代码和环境的烦恼